
Haben Sie sich jemals gefragt, wie Chatbots funktionieren und warum sie in so vielen Bereichen genutzt werden?
Wir gehen in diesem Artikel kurz darauf ein, warum ein Chatbot ein nützliches Tool für viele Einsatzbereiche sein kann und etwas ausführlicher wie er funktionert. Wir werden nicht auf das Training und die interne Funktionalität von neuronalen Netzwerken eingehen.
Der Artikel basiert auf dem Inhalt des FH-internen KI-Weiterbildungsvortrags aixpierence 01. Die aixpierence 01 bietet zusätzlich noch eine Demonstration eines Chatbots.
Warum überhaupt Chatbots?
Chatbots bieten Lehrenden im Hochschulalltag wertvolle Unterstützung, indem sie beispielsweise bei der Ideenfindung, Konzeptentwicklung und Planung von Lehrveranstaltungen helfen. Sie optimieren die Textverarbeitung durch Übersetzen, Erstellen und Strukturieren von Inhalten, was die Verständlichkeit steigern und Arbeitsprozesse effizienter gestalten kann. In der Kommunikation erleichtern sie durch E-Mail-Zusammenfassungen und sprachgesteuerte Assistenten den schnellen Austausch. Zudem bieten sie einen schnellen Zugang zu wissenschaftlichen Informationen und unterstützen beim Einstieg in neue Themenbereiche.
Gleichzeitig ist auch eine Nutzung als speziell vortrainierte Lern-Assistenz (KI-Tutor:in) für die Studierenden denkbar, wenn gleich der rechtliche Rahmen noch in Teilen abgeklärt werden muss.
Was’n Ellellemm?
LLM steht für Large Language Model. Ziel eines LLMs ist es, (menschliche) Sprache zu verstehen und zu erzeugen.
Das bedeutet, dass es mithilfe eines gegebenen Textes vorhersagen kann, welches „Wort“ mit hoher Wahrscheinlichkeit als nächstes folgt. Diese Vorhersagen sind das Herzstück der Funktionsweise eines Chatbots. Warum wir „Wort“ in Anführungszeichen setzen, wird unten erklärt.
Es funktioniert ähnlich zu den Wortvorschlägen einer Handytastatur, in der der eingetippte Kontext (hier „Hallo“) genutzt wird, um nächste Wörter vorherzusagen:
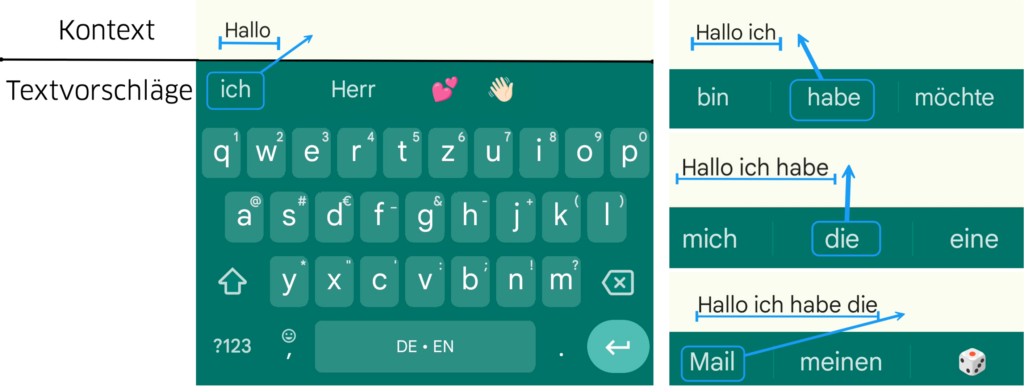
Wichtig ist, dass das LLM selbst kein spezifisches „Wort“ auswählt. Stattdessen berechnet es für jedes mögliche „Wort“ eine Wahrscheinlichkeit, die angibt, wie passend dieses Wort als nächstes wäre. Das bedeutet, das LLM erstellt lediglich eine Rangliste der möglichen Wörter nach ihrer Wahrscheinlichkeit.
Von Wörtern zu Token
Ein großes Problem bei der Vorhersage von Wörtern ist, dass es einfach so viele gibt, dass eine schnelle Vorhersage die Rechenleistung moderner Systeme übersteigt.
Allein im Deutschen gibt es mehrere Hunderttausend bis mehrere Millionen Wörter und dies nur in der Grundform. Dabei beherrschen moderne LLMs häufig mehrere Sprachen. Über all diese Wörter eine Rangliste der Wahrscheinlichkeiten zu treffen, ist aktuell nicht in einer nutzbaren Geschwindigkeit möglich.
Deswegen meinen wir wenn wir über „Wörter“ sprechen, in Wirklichkeit Token. Token sind kurze Textabschnitte ggfs. mit Satzzeichen.
Der Beispielsatz „Das Wetter ist schön“ wird in die Token „Das“, “_Wetter“, “ sch“, “ön“ und „.“ aufgeteilt. Bemerken Sie dabei, dass die Leerzeichen, z.B. bei „ Wetter“ Teil des Tokens sind.
Diese ca. 50 000 Token lassen sich in der Art kombinieren, dass jegliche Wörter und Sätze damit gebaut werden können.
Jeder Token hat eine eindeutig zugeordnete Zahl, die sogennante Token-ID, z.B. „ Wetter“ entspricht der Token-ID 19236 und „ön“ der Token-ID 526.
Vereinfacht gesagt, unterteilt der Chatbot den bisherigen Chatverlauf in seine Token und gibt die zugehörigen Token-IDs weiter an das LLM. Dieser gesamte Vorgang heißt Tokenisierung.
Das LLM nutzt dann diese IDs um eine Vorhersage für die nächste Token-Rangliste zu erzeugen. Ein spezieller Token ist der sogenannte Endtoken, der dem Chatbot signalisiert, dass eine Chatnachricht vollständig ist und nun die andere Gesprächsseite anfängt.
Was unterscheidet ein LLM von einem Chatbot?
Oft werden die Begriffe sinngleich verwendet, aber es gibt klare Unterschiede. Wir wagen einen Vergleich mit Körper und Gehirn, wobei das LLM dem Gehirn und der Chatbot dem Körper entspricht:
Der Chatbot nimmt die Eingaben der Nutzer auf und angepasst gibt sie an das LLM weiter, so wie der Körper Signale über die Sinne aufnimmt und diese in passender Form an das Gehirn weitergibt. Das LLM analysiert und generiert eine Antwort, die dann in angepasster Form (Tokenisierung) an den Chatbot gesendet und weiterverarbeitet wird, so wie der Körper Signale des Gehirns umwandelt und so mit der Umwelt interagiert.
Ablauf eines Chatbot Chats
Ein Gespräch mit einem Chatbot passiert ähnlich wie ein Gespräch auf einem Messenger Dienst, wie WhatsApp oder Signal, nur dass auf der anderen Seite kein Mensch sitzt:
- Sie schicken eine Nachricht
- Der Chatbot tokenisiert den bisherigen Chatverlauf und gibt ihn ans LLM
- Das LLM erstellt aufgrund des Kontexts eine Rangliste für die nächsten Token und gibt diese an den Chatbot
- Der Chatbot wählt einen der wahrscheinlichsten Token aus.
- Wenn der Endtoken erreicht wird, beginnt dieser Ablauf wieder von vorne, also bei 1.
- Wenn der Token nicht der Endtoken ist, wird die Antwort um diesen ergänzt und der Ablauf springt zu 2.
Häufige Fragen zu Chatbots
Warum nutzt der Chatbot nicht den wahrscheinlichsten Token, sondern nur einen der wahrscheinlichsten?
Wenn immer der wahrscheinlichste genommen wird, werden die Gespräche sehr mechanisch und unkreativ, allerdings werden sie mit dem zufälligen Wahl fehleranfälliger, z.B. wenn der Text „1+1=“ ergänzt werden soll, wird „2“ mit hoher Wahrscheinlichkeit der nächste Token sein, allerdings nicht mit hundertprozentiger.
Woher weiß der Chatbot eigentlich, was er sagt?
Alle generierten Token basieren auf einem Training für Mustererkennung. Nirgends im LLM ist eine Datenbank, mit der Informationen abgeglichen wird. Wenn Sie fragen „Was ist ein Apfel?“, erhalten Sie meist eine gute und saubere Definition, die aber nicht direkt im LLM gespeichert ist, sondern durch Training auf solchen Daten erstellt wird. Die Token werden einzeln generiert, so dass das Ziel der Generierung nicht vorab geplant wird.
Wie liefert das LLM Antworten, wenn es nur den Chatverlauf sieht?
Das LLM ist darauf trainiert eine Geschichte weiterzuschreiben. Diese Geschichte ist in dem Fall eines Chatbots immer eine von zwei Instanzen, die sich austauschen.
Der Chatbot liefert aber auch noch über einen gesonderten Prompt (Meta-Prompt), den wir nicht einsehen können, noch mehr Kontext für das LLM. Unter anderem wird darin festgelegt, dass das der Chatbot zusammen mit dem LLM die Rolle eines hilfsbereiter Assistenten übernimmt.
Wie lange kann ein Chat werden?
Ein Chatbot kann aufgrund der begrenzten Kontextlänge eines LLMs nicht beliebig lange Gespräche führen. Wenn die maximale Kontextlänge erreicht wird, vergisst der Chatbot die älteren Teile des Chats. Allerdings sind diese Kontextfenster häufig hunderttausende Token lang, was etwa einem kurzen Roman entspricht.
Mein Chatbot hat Funktionalitäten, die hier nicht erwähnt werden?
Wir versuchen die allgemeinen Fähigkeiten von Chatbots darzustellen. Viele Chatbots haben zusätzliche Fähigkeiten, wie einen Sprachmodus, Generierung von Bildern und anderen Dateien, Input von Dateien oder Internetsuchen (RAG), Erinnerung über mehrere Chats und noch vieles mehr, die für das grundlegende Verständnis nicht relevant sind.
Limitationen und Halluzinationen
Chatbots können beeindruckende Antworten geben, aber diese beruhen auf Wahrscheinlichkeitsberechnungen. Sie verfügen über kein tatsächliches Verständnis der Welt. Deshalb kann es zu Fehlern, sogenannten „Halluzinationen“, kommen, bei denen der Chatbot plausible, aber inhaltlich falsche Aussagen macht.
Die eigene (Fach-)Expertise sollte vorhanden sein, um die die Ausgaben eines Chatbots nachzuvollziehen zu können..
Tipp: Ein Chatbot denkt nur bis zum nächstes Token. Dadurch kann er nicht einfach planen, was er schreiben möchte.
Dies kann verbessert werden, beispielsweise mit dem Chain of Thought Prompting: Damit fordern wir den Chatbot auf erst einen Gedankenablauf zu erstellen oder geben diesen selbst vor. Dann basiert die nächste Antwort auf diesem Gedankenablauf. Einige Chatbots führen diesen Prozess bereits automatisch durch.
Der Chatbot ist realitätsfremd. Er kennt nicht die Umwelt, weiß nicht wer Sie sind oder wofür Sie ihn nutzen möchten. Daher ist es wichtig, dass Sie ihren relevanten Kontext einbringen müssen um einen guten Output zu generieren. .
Fast alle LLMs sind von privaten Firmen trainiert und die für das Training genutzten Daten sind nicht einsehbar. Dadurch entsteht ein nicht einschätzbares Bias in den Antworten. Weiterhin wissen wir auch nicht, welche anderen Moderationsmöglichkeiten einzelne Chatbots eingebaut haben.
Achtung: Die meisten Gratisversionen, aber auch viele Bezahlversionen nutzen Ihre Eingaben als Trainingsdaten für Ihre neuen Chatbots.

Jonas Gilz
Studierter Mathematiker (M.Sc.) Mitglied des Arbeitsbereichs ZHQ | E-Learning.

Christoph Horst
> Koordination Digitalisierungsoffensive Lehren & Lernen der FH Aachen
> Fachlehrender im Fachbereich Chemie und Biotechnologie